Das zuvor beschriebene Grundtraining ist ein wichtiger Bestandteil der KI-basierten Suchmaschinen, um Texteingaben mit Sprache zu verstehen und darauf antworten zu können. Hierfür kann für die Suchmaschine ein eigenes Large Language Modell trainiert oder auf ein vorhandenes aufgebaut werden. Bing Chat beispielsweise nutzt GPT-4 von OpenAI als Grundlage.
Die meisten Daten zum Training von GPT-4 sind jedoch nicht öffentlich einsehbar, demzufolge ist es notwendig, ebenfalls das Vorgängermodell zu untersuchen. Daher werden im Folgenden der Energieverbrauch des Grundtrainings der jeweiligen GPT-4 und GPT-3 Modelle analysiert. Hauptfaktoren des Energieverbrauchs sind der angewandte Trainingsalgorithmus, die Anzahl der Parameter des KI-Modells, die eingespeiste Datenmenge sowie die verwendete Hardware.
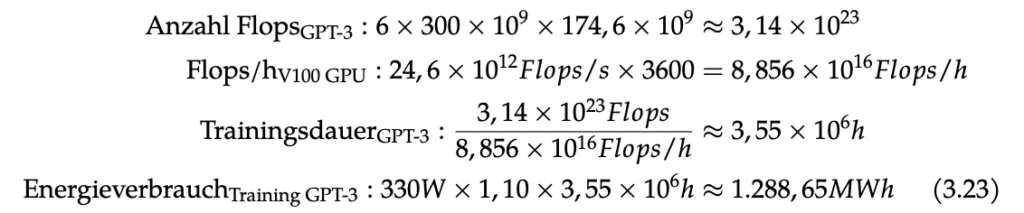
Die finale GPT-3 Version besitzt 174,6 Milliarden Parameter und wurde mit 300 Milliarden Token trainiert. Für das Training wurden pro Parameter pro Token 6 Rechenoperationen (Floating Point Operations) durchgeführt, woraus sich 314 Trilliarden benötigte Flops für das Training ergeben. Für das Training von GPT-3 wurden Nvidia V100 GPUs innerhalb eines Clusters mit hoher Bandbreite genutzt, das Microsoft bereitgestellt hat.
In einer Studie wurde angegeben, dass die V100 GPU 300 Watt für den Betrieb benötigt und dass unter Berücksichtigung der weiteren Hardware, wie Speicher, Host CPU und Kühlung von 330 Watt pro GPU ausgegangen werden kann. Eine einzelne V100 GPU benötigt hierfür eine Trainingsdauer von 3,55 Millionen Stunden. In der Praxis können dabei mehrere GPUs parallel genutzt werden, wodurch sich die Trainingsdauer auf mehrere GPUs verteilt. Für den Energieverbrauch kann jedoch mit der Trainingsdauer einer einzelnen GPU gerechnet werden, da sich die Anzahl der verwendeten GPUs in der Rechnung ausgleicht.
Unter Berücksichtigung der Energieeffizienz des Rechenzentrums, der PUE mit dem Faktor 1,10, der Rechenleistung der V100 GPU von 24,6 TFlops/s ergibt sich somit ein Gesamtenergieverbrauch von 1288,65 MWh für das Training von GPT-3.
Unter Einbezug des dreimal so langen Entwicklungszeitraums von GPT-4 kann auch eine deutlich höhere Parameterzahl angenommen werden. Bei einem dreifachen Entwicklungszeitraum ist es möglich, ebenfalls die Steigerung der Parameterzahl dreifach durchzuführen. Somit würde sich eine geschätzte Parameterzahl von 275,36 Billiarden Parameter ergeben. Diese Zahl übertrifft jedoch stark die Schätzungen von 1 Billion bis 100 Billionen. Die höheren Schätzungen gehen nicht von einer dreifachen Steigerung aus, sondern nähern sich einer 1,35-fachen Steigerung an und würden 107,41 Billionen Parameter ergeben.

Mit der größeren Schätzung der Parameterzahl von ca. 107,41 Billionen, bei gleicher Tokenanzahl und weiterhin 6 Flops pro Parameter pro Token ergibt sich für das Training ein Rechenaufwand von 496 Quadrillionen Flops. Somit ergeben sich bei der gleichen verwendeten Hardware eine Trainingsdauer von 5,6 Milliarden Stunden und ein Energieverbrauch von 2,03 TWh für das Training.