Die Generierung einer natürlichen, textbasierten Antwort gehört zu den Hauptmerkmalen einer KI-basierten Suchmaschine. Während dieses Prozesses wird die Antwort speziell für die Anfrage des Nutzers generiert. Der Energieverbrauch der Generierung hängt dabei maßgeblich von der dafür benötigten Rechenleistung, des Antwortumfangs sowie der Anzahl der Nutzeranfragen ab.
Die durchschnittliche Antwortlänge von Bing Chat beträgt 202,25 Zeichen, was ca. 31 Wörtern entspricht. Bei 5 Wörtern pro Sekunde benötigt Bing Chat 6,2 Sekunden für eine Antwort. Dies ist vergleichbar mit den 5,2 Sekunden, die Bing Chat durchschnittlich benötigt, wenn keine Suchanfragen durchgeführt werden. Den Unterschied von einer Sekunde lässt sich durch die unterdurchschnittliche Antwortlänge bei einfacheren Antworten erklären, da hierbei Prozesse vor der tatsächlichen Generierung stärker ins Gewicht fallen.
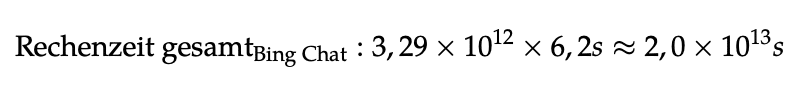
Um KI-basierte Suchmaschinen mit Index-basierten Suchmaschinen vergleichen zu können, wird von der gleichen Anzahl an jährlichen Anfragen ausgegangen. Im Jahr 2016 wurden 3,29 Billionen Suchanfragen an Google gerichtet. Multipliziert man die Anzahl der Suchanfragen mit der jeweils benötigten Rechendauer von 6,2 Sekunden, ergibt sich eine Gesamtrechenzeit von 20 Billionen Sekunden (634.195 Jahre).
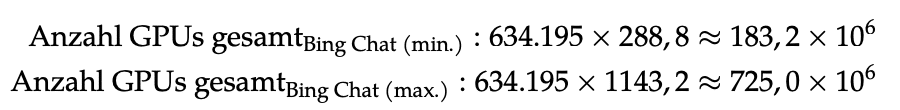
Um diese Rechenzeit innerhalb eines Jahres erbringen zu können, wird 634195-mal die zuvor berechnete Anzahl an GPUs benötigt, die durchgehend und zeitgleich die Anfragen bearbeiten. Daraus ergibt sich eine benötigte Gesamtanzahl von 183,2 Millionen bis 725,0 Millionen GPUs.

Bei einem Energieverbrauch von 330W pro GPU und einem von 1,10 sowie einer Rechendauer von einem Jahr ergibt sich für 183,2 Millionen GPUs ein jährlicher Energieverbrauch von 583 TWh für die Antwortgenerierung von Bing Chat. Für den Betrieb von 725 Millionen GPUs werden 2305 TWh an Energie benötigt.
Diese hohen Werte sind auf die große Anzahl zu bearbeitender Anfragen zurückzuführen sowie auf die Tatsache, dass von der Nutzung eines sehr großen KI-Modells ausgegangen wird. Bei der Nutzung eines kleineren KI-Modells werden dementsprechend weniger GPUs für den Rechenprozess benötigt.